DATABASE SYSTEMS
Advanced Database Syllabus
- Concurrent Access Control
Concurrent and serialisability
Locking techniques including… 2 phase locking,
Locking granuality,
Deadlock,
Detection and Prevention
Rollback and restart criteria
Timestamp ordering policy and implementation
- Recovery
- Security
- Practical DB Management
- Trends in DB Technology
1st Lecture : Monday / 24 / Sep / 2001
What is a Database?
A Database system may simply be described as a computerized record-keeping system. The DB may be regarded as an electronic filing cabinet, whereby the user can perform various operations, such as:
- Adding new files to the DB
- Inserting new data to existing files
- Retrieving data from existing files
- Updating data in existing files
- Deleting data in existing files
- Removing existing files from the DB
Introductory Example:
The ‘CELLAR’ Table
Bin |
Wine |
Producer |
Year |
QTY |
Ready |
|
2 |
Char |
Mouchau |
92 |
3 |
99 |
|
4 |
Char |
P. Mason |
92 |
2 |
98 |
|
6 |
Reisling |
P. Mason |
89 |
4 |
98 |
|
7 |
Cab. Sauv. |
Glen Ellen |
93 |
2 |
99 |
|
8 |
Cab. Sauv. |
Wolf Bass |
87 |
1 |
99 |
|
22 |
Merlot |
Glen Ellen |
95 |
6 |
99 |
|
24 |
Merlot |
Red Nun |
95 |
7 |
96 |
|
30 |
Rioja |
Olde Seville |
98 |
4 |
99 |
|
33 |
Rioja |
Stone Street |
89 |
2 |
94 |
Info Retrieved… SQL (type of software)
SELECT BIN, WINE, QTY
FROM CELLAR
WHERE READY < 99
Result
Bin |
Wine |
QTY |
|
4 |
Char |
2 |
|
6 |
Reisling |
4 |
|
24 |
Merlot |
7 |
|
33 |
Rioja |
2 |
Working with the data
INSERT
INTO CELLAR (BIN, WINE, PRODUCER, YEAR, QTY, READY)
VALUES (28, ‘Pinot Noir’, ‘S.E. Exports’, 93, 10, 02)
UPDATE CELLAR
SET READY = 99
WHERE BIN = 24
DELETE
FROM CELLAR
WHERE BIN = 6
Resultant Database
Bin |
Wine |
Producer |
Year |
QTY |
Ready |
|
2 |
Char |
Mouchau |
92 |
3 |
99 |
|
4 |
Char |
P. Mason |
92 |
2 |
98 |
|
7 |
Cab. Sauv. |
Glen Ellen |
93 |
2 |
99 |
|
8 |
Cab. Sauv. |
Wolf Bass |
87 |
1 |
99 |
|
22 |
Merlot |
Glen Ellen |
95 |
6 |
99 |
|
24 |
Merlot |
Red Nun |
95 |
7 |
96 |
|
28 |
Pinot Noir |
S.E. Exports |
93 |
10 |
02 |
|
30 |
Rioja |
Olde Seville |
98 |
4 |
99 |
|
33 |
Rioja |
Stone Street |
89 |
2 |
94 |
Database Management System
(DBMS)
- A very large integrated collection of data
- A DBMS is a software package designed to store and manage DB’s
Advantages of using a DBMS
- Promotes data independence and efficient access
- Reduces application and development time
- Data integrity and security
- Concurrent access
Friday / 28 / 09 / 01
Fact
- Volume
- Speed
- Reduced errors
- Correctability
Possible advantages
- Data standardization
- Currency
- Flexible security
Database architecture
Database definition: “Collection of persistent data that is used by the application system
of some enterprise”
Data
- Persistent
- Single / multi-user access
- Data integration
- Data sharing
- Distributed
Database vocabulary
Data: data consists of a series of facts or statements that may have been collected, stored, processed and/or manipulated but have not been ordered or placed into context. When data is organized, it becomes information. Information can be used to draw generalized conclusions or knowledge
Database architecture
Many persons are involved in the design, use and maintenance of a large DB with a few hundred users.
- DB Administrators (DBA)
- DB Designers
- End-users
· Casual
· Naïve or Parametric
· Sophisticated
· Stand-alone
- System analysts and Application Programmers(Software Engineers)
Database
Administrator
The DBA is responsible for:
- Authorizing access to the DB
- Coordinating and monitoring its use
- Acquiring software and hardware resources as needed
The DBA is accountable for problems such as a breach of security or poor system response time
Database designers
- DB designers are responsible for identifying the data to be stored in the Db and for choosing appropriate structures to represent and store this data
- It is the responsibility of DB designers to communicate with all appropriate DD users, in order to understand their requirements, and to come up with a design that meets these requirements.
- The final DB design must be capable of supporting the requirements of all user groups
End-users
End-users are the people whose jobs require access to the Db for querying, updating and generating reports; the DB primarily exists for their use
Categories of End-users:
- Casual End-users: Occasionally access the DB, but they may need different information each time. Examples of such users may be middle or high-level managers or occasional browsers. They use a sophisticated DB query language to specify their requests
- Naïve or Parametric End-users:
their main job function revolves around constantly querying and updating
the Db, using standard types of queries and updates – called “Canned
Transactions”. Examples of such
users
- Bank tellers check account balances and post withdrawals and deposits
- Reservation clerks for airlines, hotels and car rental companies check availability for a given request and make reservations
§ Sophisticated End-users: thoroughly familiarize themselves with the facilities of the DBMS so as to implement their applications to meet their complex requirements. Examples of such users include Engineers, Scientists and Business Analysts.
§ Stand-alone users: maintain personal DB’s by using ready-made program packages that provide easy-to-use menu or graphics-based interfaces. Example: The user of a tax package that stores a variety of personal financial data for tax purposes
§ System Analysts and Application Programmers(Software Engineers):
· System Analysts determine the requirements of end-users, especially naïve and parametric end-users, and develop specifications for canned transactions that meet these requirements
· Application Programmers implement these specifications as programs; then they test, debug, document and maintain these canned transactions
Wed / 03 / 10 / 01
Data Models, Schemas and Instances
A fundamental characteristic of a DB is that: it provides some level of data abstraction by hiding details of data storage that are not needed by most DB users
What is a Data Model?
A data model is a collection of concepts that can be used to describe the structure of a DB and provides to achieve this abstraction
What is meant by the structure of a DB?
The data types, relationships and constraints that should hold the data
Most data models include a set of basic operations for specifying updates and retrievals on the DB
Categories of Data Models
1. High-level
are conceptual data models (used by end-users)
2. Low-level or physical data models (use by computer specialists)
3. Representational(or implementation) data models (used by end-users and computer specialists)
Many DM’s exist, and are categorized according to the types of concepts they use to describe the DB structure
è High-level or conceptual DM’s provide concepts that are close to the ways many
users perceive data
è Low-level or physical DM’s provide concepts that describe the details of how data is stored in the computer
Concepts that are provided by low-level DM’s are generally meant for: computer specialists and end-users.
Between high-level and low-level DM’s, there is
è Representational(or implementation) DM’s which provide concepts that may be
understood by end-users but that are not too far removed from the way data is organized within the computer.
Conceptual DM’s use concepts such as entries, attributes and relationships
Entity
An entity represents a real-world object or concept, such as an employee or a project that is described in the DB.
Attribute
An attribute represents some property of interest that further describes an entity, such as an employees name or salary
Relationship
A relationship among 2 or more entities represents an interaction among the entities, for example, a works on relationship between an employee and a project
Employee Employee name
![]()
![]()
![]()
entity works on

Project
Ex
of a relationship
Friday / 5 / 10 / 01
Schemas
The description of a DB is called a DB Schema
The DB Schema is specified during the DB’s design and is not expected to change frequently
Schema changes are usually needed as the requirements of the DB applications change
New DB systems include operations for allowing Schema changes
The Schema change process is more difficult than simple DB updates
Most data models have certain conventions for displaying the Schemas as diagrams. A display schema is called a schema diagram
Examples of schema diagrams
Student
![]()
Course

Each object in the schema is called a schema construct.
The actual data in a DB may change quite frequently.
For ex: In a Student DB every time a new student is added or a new grade for
a student is entered
The data in a DB at a particular moment in
time is called a DB state or snapshot
It is also called the current state of occurrences or instances in the DB.
Everytime a record is inserted or deleted the DB changes from one state into another. It is important to note the distinction between a DB schema and a DB state.
When a new DB is defined, the DB schema is specified only to the DBMS. At this point, the corresponding DB state is the empty state with no data.
The initial state of the DB is when the DB is first populated or loaded with the initial data
At any point in time the DB has a current state
The DBMS is partly responsible for ensuring that every state of the DB is a valid state
Valid state = a state that satisfies the structure specified in the schema
Specifying a correct schema to the DBMS is extremely
important, and the schema
must be designed with the utmost care.
DBMS Architecture and Data Independence
3 important characteristics of the DB approach
- Insulation of programs and data
- Support of multiple user views
- Use of a catalog to store the DB descriptions (schema)
A 3-schema architecture exists to help achieve and utilize the characteristics.
The goal of the 3-schema architecture is to separate the user applications and the physical DB.
Schemas can be defined at 3 levels
- The internal level has an internal schema, which describes the physical storage structure of the DB. The internal schema uses a physical data model and describes the complete details of data storage and access paths for the DB.
- The conceptual level has a conceptual schema, which describes the structure of the
whole DB for a community of users. The conceptual schema hides the details
of the physical storage structures and concentrates on describing
entities, data types, relationships, user operations and constraints.
A high-level DM or an implementation DM can be used at this level.
- The internal or view level includes a number of external schemas or user views.
Each external schema describes the part of the DB that a particular user group is interested in and hides the rest of the DB from that user group.
A high-level DM or an implementation DM can be used at this level
Monday / 8 / 10 / 01
(ILLUSTRATION
of the 3-SCHEMA)
External View External View
End-users


Describes part of the DB that a particular user group is interested
Conceptual
Model
![]()
![]()
![]() Describes structure
of the whole DB
Describes structure
of the whole DB
Logical data
independence
can change
Internal
Schema
![]()
![]()
![]()
![]()
Describes the physical storage structure of
the DB
Physical data
independence
can change

Stored DB
Schema = Description
Data independence (DI)
DI is defined as the capacity to change the schema at 1 level of the Db system without having to change the schema at the next higher level
There are 2 types of DI
- Logical DI
- Physical DI
Logical DI
LDI is the capacity to change the conceptual schema without having to change external schemas or application programs
The conceptual schema may be changed to expand the DB(by adding a record type or data item) or to reduce the DB(by removing a record type or data item)
Logical DI = Change the conceptual schema
Physical DI
PDI is the capacity to change the conceptual (or external) schemas.
Changes to the internal schema may be needed because some physical files have to be reorganized. For ex. – by creating additional access structures to improve the performance of retrieval or update.
Physical DI = Change the internal schema
DB languages and Interfaces
Once the design of the DB is completed, the next step is to specify the Conceptual and Internal schemas for the DB.
A language called the Data Definition Language(DDL) is used by the DBA and by DB designers to define both schemas.
The DBMS will have a DDL compiler whose function is to process DDL statements in order to identify descriptions of the schema and to store the schema description in the DBMS catalog.
DBMS Interfaces
1) Menu based interfaces for browsing
2) Forms based interfaces
3) Graphical user interfaces
4) Natural language interfaces
5) Interfaces for parametric users
6) Interfaces for the DBA
1. Menu based interfaces for browsing
These interfaces present the user with lists of options, called menus that lead the user through the formulation of a request
2. Forms based interfaces
A FBI displays a form to each user. Users can fill out all of the form entries to insert new data, or they fill out only certain entries, in which case the DBMS will retrieve matching data for the remaining entries.
3. Graphical user interfaces
A GUI typically displays a schema to the user in a diagrammatic form
4. Natural language interfaces
These interfaces accept requests written in English and “attempt” to understand them
5. Interfaces for parametric users
Parametric users(bank tellers) often have a small set of operations that they must perform repeatedly. Goal of the interface is to have abbreviated commands; minimizing the number of key-strokes
6. Interfaces for the DBA
DB systems that contain privileged commands that can be used by the DBA’s staff only.
Ex. of commands
· Creating accounts
· Setting system parameters
· Granting account authorisation
· Changing a schema
Thursday / 18 / 10 / 01
Data Models
A DM represents the organization itself
A DM should consist of 3 parts:
1. A STRUCTURAL part – consisting of a set of rules according to which DB’s can be constructed
2. A MANIPULATIVE part – defining the types of questions that are allowed on the data. I.e. updating, retrieving data from the DB
3. A set of INTEGRITY RULES – which ensures that the data is accurate
The purpose of a DM is to represent data and to make the data understandable
3 categories of DM exist:
1. Object-based
Data Models:
Use concepts such as entities, attributes and relationships
Types of Object-based DM’s:
a) Entity – Relationship
b) Semantic
c) Functional
d) Object-orientated
- The Entity – Relationship model emerged as one of the main techniques for DB design.
- The Object-orientated DM extends the definition of an entity to include not only the attributes that describe the state of the object but also the actions that are associated with the object, that is its behavior.
2. Record-based
DM’s:
The DB consists of a number of fixed-format records possibly as differing types. Each record type defines a fixed number of fields, and typically of a fixed length.
There are 3 types of record-based DM’s:
a) Relational DM Links to traditional file
b) Network DM processing concepts
c) Hierarchical DM more evident
A) Relational DM: Data and Relationships are represented as tables, each of which
have a number of columns with a unique name
BRANCH
E.g.:
|
Branch No |
Street |
City |
Post Code |
|
|
22 Deer Rd |
London |
SW14EH |

STAFF
|
Staff No |
F Name |
L Name |
Position |
Sex |
D.o.b. |
Branch No |
|
SL21 |
John |
White |
Manager |
M |
01/Oct/1945 |
B005 |
BRANCH DB and STAFF DB are related through Branch No:
BRANCH and STAFF details:
So employee John White is a manager with a salary of £30,000, who works at Branch No B005, which from the first table is at 22 Deer Pond in London
NOTE: There is a relationship between STAFF and BRANCH. A BRANCH office has STAFF
B) Network DM: in the network model, data is represented as collections of records,
and relationships are represented by sets
|
SL41 |
Julie |
Lee |
… |
Assistant |
9000 |
![]()
|
B005 |
|
|
|
SL21 |
John |
White |
… |
Manager |
30000 |
Branch No is the connection in all this data
They both work in same branch
C) Hierarchical DM: this is a restricted type of Network model.
Again, data is represented as collections of records, and relationships are represented by sets
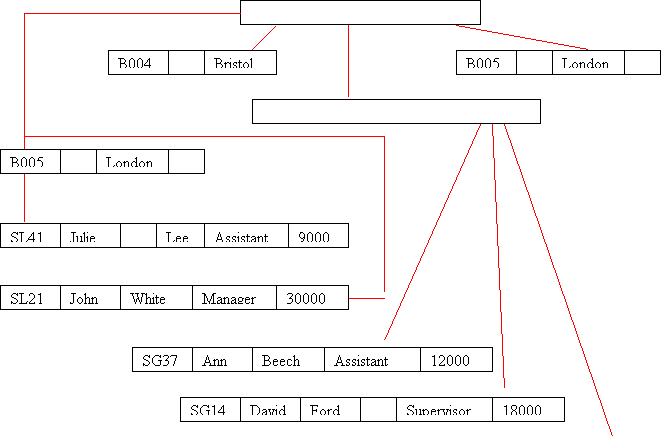
![]()
Monday / 22 / 10 / 01
Functions of a DBMS
1. Data storage, retrieval and update
2. A uses accessible catalogue
3. Transaction support
4. Concurrency control services
5. Recovery services
6. Authorisation services
7. Support for data communication
8. Integrity services
9. Services to promote data independence
10. Utility services
1 A DBMS must furnish users with the ability to share, retrieve and update data in the DB
2 A DBMS must furnish a catalogue in which descriptions of data items are shared and which is accessible to users
A system catalogue should hold data about the users and applications. It is (the catalogue)
Expected to be accessible to users as well as to the DBMS
A system catalogue, or data dictionary, is a repository of information describing the data in the DB: It is, the data about the data or the meta-data. The amount of information and the way the information is used vary with the DBMS
Typically, the System Catalogue stores:
· Names, types and sizes of data items
· Names of relationships
· Integrity constraints on the data
· Names of authorized users who have access to the data
· External, conceptual and internal schemas
· Usage statistics such as the frequency of transactions and counts on the number of accesses made to objects in the DB
Benefits of a System Catalogue
· Information about the data can be collected and stored centrally. This helps to maintain control over the data as a resource.
· The meaning of data can be defined which will help other users understand the purpose(s) of the data.
· Communication is simplified, since exact meanings are stored. The System Catalogue may also identify the user or users who own or access the data
· Changes in the DB can be recorded
· The impact of a change can be determined before it is implemented since the System Catalogue records each data item, all its relationships and all its users
3 Transaction support
A DBMS must furnish a mechanism, which will ensure that either all the updates corresponding to a given transaction are made or that none of them is made.
A transaction is a series of actions, carried out by a single user or application program, which accesses or changes the contents of the DB.
Ex: To ADD, UPDATE, DELETE
4 Concurrency control services
A DBMS must furnish a mechanism to ensure that the DB is updated correctly when multiple users are updating the DB concurrently
Concurrent access is relatively easy if all users are only reading data, as there is no way in which they can interfere with one another.
However, when 2 or more users are accessing the DB simultaneously and at least one of them is editing data, there may be interference that can lead to inconsistency in the data
5 Recovery services
A DBMS must furnish a mechanism for recovering the DB in the event that the DB is damaged in any way
6 Authorization
services
A DBMS must furnish a mechanism to ensure that only authorized personnel can access the DB
7 Support
for data communication
A DBMS must be capable of integrity with communication software
8 Integrity
services
A DBMS must furnish a means to ensure that both the data in the DB and changes to the data follows certain rules:
DB integrity refers to the correctness and consistency of stored data
Integrity is usually expressed in terms of correctness
e.g. we may want to specify a constraint that no number of staff can
manage more than 100 properties at a time
Thursday / 25 / 10 / 01
The Relational Model
- In the relational model, all data is logically structured within relations (tables).
- Each relation has a name and is made up of named attributes (columns) of data
- Each tuple (row) contains 1 value per attribute
- The strength of the relational model is its logical structure
Relational data structure
Relation
A relation is a table with columns and rows
Attributes
An attribute is a named column of a relation. In the relational model, relations are used to hold information about the objects to be represented in the DB.
A relation is represented as a 2-D table, in which the rows of the table correspond to attributes. Attributes may appear in any order

![]()
|
|
|
|
|
||||
|
Relation |
|
|
Cardinality |

Degree


|
Degree |
Foreign key
![]()
![]()
Primary key
|
|
Branch No |
A column contains values of a single attribute:
E.g. The Branch No columns contain only numbers of existing branch offices
Tuple
This is a row of a relation. The elements of a relation are the rows or tuples in the table. Tuples can appear in any order.
Degree
The degree of a relation is the number of attributes it contains.
E.g. in the branch relation, it has degree 4. this means that each row of the table is a 4-tuple containing 4 values.
A relation with only 1 attribute would be called a unary relation.
A relation with 3 attributes is called ternary, and after that the term n - ary is used.
Cardinality
The cardinality of a relation is the number of tuples it contains. The number of tuples is called the cardinality of the relationship and this changes as tuples are added and deleted.
Relational
DB
A collection of normalized relations with distinct relation names
Alternative Terminology
A relation may be referred to as a file, the tuples as records and the attributes as fields
Normal terms Alternative 1 Alternative 2
Relation Table File
Tuple Row Record
Attribute Column Field
Properties of relations
A relation has the following properties:
- The relation has a name that is distinct from all other relation names in the DB
- Each cell of the relation contains exactly 1 single value
- Each attribute has a distinct name
- The values of an attribute are all from the same domain
(Domain = the set of allowable values for 1 or many attributes)
- Each tuple is distinct – there are no duplicate tuples
- The order of attributes has no significance
Relational keys
There are no duplicate tuples within a relation therefore we need to be able to identify one or many attributes (called relational keys) that uniquely identifies each tuple in a relation
Super Key
An attribute, or set of attributes, that uniquely identifies a tuple within a relation
Primary Key
The candidate key that is selected to identify each row uniquely. This means that a relation always has a primary key
Foreign Key
An attribute, or set of attributes, within
1 relation that matches the candidate key of some (possibly the same) relation
Friday / 26 / 10 / 01
SQL
SQL – Structured Query Language
Objectives of SQL
Ideally a DB language should allow the user to:
· Create the Db and relation structures
· Perform basic management tasks, such as the insertion, editing, and the deletion of data from the relations
· Perform both simple and complex queries
A DB language must perform the tasks with minimal user effort, and its command structure and syntax must be relatively easy to learn.
Finally, the language must be portable, that is, it must conform to some recognized standard so that we can use the same command structure and syntax when we move from one DBMS to another.
SQL is intended to satisfy these requirements
SQL has 2 major components:
è DDL (Data Definition Language): for defining the DB structure and controlling access to the data
è DML (Data Manipulation Language): for retrieving and updating data
SQL is:
- A non-procedural language. You specify what information you want rather than how to get it
- Essentially free-format, which means that parts of statements do not have to be typed at particular locations on the server
- The command structure consists of standard English words such as
CREATE TABLE, INSERT, DELETE, etc…
E.g.
CREATE TABLE staff(staffno VARCHAR(5), Lname VARCHAR(15), salary DECIMAL(7,2));
INSERT INTO staff VALUES (‘SG16’, ‘Brown’, 8300);
SELECT staffno, Lname, salary
FROM staff
WHERE salary < 10000;
An SQL statement consists of RESERVED words and USER-DDEFINED words.
Reserved words are a fixed part of the SQL language and have a fixed meaning. They must be spelt EXACTLY as required and cannot be split across lines.
User-defined words are created by user – according to certain syntax rules! They represent the names of various DB objects such as tables, columns, etc…
Most components of an SQL statement are
not case sensitive.
The one important exception to this rule is that literal character data must be types exactly as it appeared in the db.
E.g. if we store a persons name as ‘John’ and then search for it using the string ‘JOHN’, the row will not be found.
SQL is the first and, so far, the only standard Db language to gain wide acceptance.
The ISO SQL standard does not use terms of relations, attributes and tubles. Instead it uses the terms tables, columns and rows.
SQL allows the table produced as the result of the select statement to contain duplicate rows. It imposes an ordering on the columns, and it allows the user to order the rows of a table.
SQL statements
- Upper-case letters are used to represent words and must be spelt exactly as shown
- Lower-case letters are used to represent user-defined words
- A vertical bar ( | ) indicates a choice among alternatives. E.g. A | B | C
- Curly braces indicate a required element. E.g. {A}
- Square brackets indicate an optional element e.g. [A]
Literals
- Literals are constants that are used in SQL statements.
- Literals may be enclosed in ‘single quotes’ or may not.
- All non-numeric data items must be enclosed in single quotes
e.g. inserting data using literals into a table
INSERT INTO PropertyForRent (PropertyNo, Street, City, PostCode,
Type, Rooms, Rent, OwnerNo, StaffNo, BranchNo)
values (‘PA14’, ’16 Holland’, ‘Aberdeen’, ‘AB75SU’, ‘House’, 6,
650.00, ‘CO46, ‘5A9’, ‘B0007’);