
| CA437 Multimedia Information
Retrieval Essay "Searching the Web" |
An Insight into Search Engine's, WebCrawler's, Meta-Search
Engines and Web Query Languages.
Name:
David Reade
Student No:
99755629
Class:
CASE4
This essay tries
to give an informative description of the current state of the Internet
along with the new and old technologies being used throughout the
area of information retrieval with relation to the World Wide Web.
Some of the ideas and thoughts in this publication stem from my own
experiences while others stem from the knowledge and experience of
others. I have outlined a list of references which have been consulted
throughout the production of this publication.
In this piece I have chosen to produce a detailed analysis of Search
Engines specifically relating to their history, architecture, ranking
algorithms and linkage analysis. I have also discussed the work done
by WebCrawler's and given a short history of the first WebCrawler
created by Brain Pinkerton. I have also chosen to analyse the use
of newer technologies such as Web Query Languages used in Internet
searching.
The final section is on my conclusions and I have developed my conclusions
based on my own observations and on any relevant data which I have
read from books and on the World Wide Web itself. It finishes by discussing
the future development of the Web and of the future role which search
engines will have to take.
I hereby certify
that the work presented and the material contained herein is my own
except where references to other material are stated. General content
references are contained in section 7.
| 1.
Introduction |
|
| 2.
Search Engines |
2.1 How they work
2.1.1 Architecture
2.1.2 Ranking Algorithms
2.2 Search Engine History
2.2.1 TimeLine
|
| 3.
WebCrawler's |
3.1 How they work
3.2 History
|
| 4.
Meta-Search Engines |
|
| 5.
Web Query Languages |
|
| 6.
Conclusions |
|
| 7.
References |
|
The World Wide Web has in just a few short years become a vast global
information resource which is not only of use to individual people
but of vital importance to the running of the ever increasing business
sector within the global economy. The rapid growth of the Internet
has resulted in the development of a large, unstructured database
with many different search and retrieval methods and tools, all trying
to optimise one basic core feature: fast retrieval of relevant information.
For example the basic key metrics of search performance in relation
to search engines are relevance, freshness and index size.
Search Engines,
Meta-Search Engines, WebCrawler's, using Web Query Languages and simply
browsing are all methods which any user of the web can avail of to
retrieve relevant information. Each of these methods has its advantages
and its disadvantages but none of them provide a completely effective
tool as it is impossible to accurately measure relevance of data all
of the time. The web in its current form poses a number of challenges
relating mainly to the actual data and problems relating to the user
and their interaction with the retrieval system. In other words the
problem with people and data is that people differ and with that,
opinion's on the relevance of data differs.
Some of the problems
relating to the Web and the storage of data are detailed in table
1:
| 1.Size |
The web is continuing to grow exponentially with no one certain what exactly it will end up as
.
|
| 2.Distribution |
The Web is spread out
over various different platforms and computers and with different
standards for each different location. This came about because
nobody planned for the development of the Web, nobody sat down
and carefully developed a set of guidelines which would have
ensured a better state of affairs today. This is easy to write
about in hind sight but nobody foresaw the effects the Web would
have on the world and it is doubtful that even careful planning
at the highest levels could have controlled something which
grew globally so rapidly.
|
| 3. Volatility |
The Web is easy to become
a part of but at the same time it is easy to disappear from.
Any user of the Web knows the frustration of following redundant
links which could potentially have housed the data which was
being searched for.
|
| 4. Structure |
The Web contains a vast
amount of repetition somewhere in the region of 30% with semantic
redundancies being possibly even larger. The Web is a very bad
implementation of a hypertext system as it has no pre-defined
conceptual model behind it which results in a weak structure
with little consistency to data and hyperlinks.
|
| 5. Quality |
Anybody can
submit content to the Web and this is all well and good when
it comes to freedom of speech but when it comes to development
of quality data there is no pre-submission checks which ensure
the validity and grammatical quality of the data being submitted.
|
| 6. Heterogenous
Data |
The World is not a one
dimensional place where everything is standardised and working
in harmony but a balance needs to be met in order for the world
to function. The World Wide Web is exactly the same as it has
to deal with various real world problems such as the different
languages and alphabets of the world. These problems exist in
the real world but are made more acute by the fact that they
are no longer restricted by the physical barrier of space and
distance. The Web also has to deal with different media types
on multiple formats and platforms.
|
The tools developed
thus far do however try to effectively overcome the problems of the
web and provide an easy to use service which is effective at retrieving
relevant information.
My first experience
of trying to find information on the internet was at secondary school
when it was still a relatively new phenomenon. At that time a teacher
introduced me to Alta Vista and I remember thinking that the computer
was smart, when at first it came back with relevant hits, but my opinion
changed and I became more frustrated when I felt that the computer
did not understand what I was asking, as it seemed to return documents
which were clearly not relevant to my query. This was however at a
time when I had no concept of browsers or crawlers or html or anything
to do with the web and I never stopped to think what was going on
behind the scenes, why did the computer not 'understand' what I was
asking it?. This is still the case for many people when they first
attempt to search the web but understanding how search tools work
is vital in allowing the user to effectively retrieve data, or in
other words allowing the user to ask a question which the computer
will be able to 'understand' and hopefully 'answer'.
The exponential
growth of the internet has resulted in the need for new and different
search tools and methods being developed. These tools must be user
friendly and meet the needs of the time. Search Engines were one of
the first solutions to the problem of information retrieval and at
present, high speed, well structured engines such as Google provide
an effective searching tool most of the time. The problem is that
no-one can accurately predict what form the web will take over the
next few years therefore no-one can pre-judge the relevance of Google
in its current form to the web of tomorrow.
People now recognise
the need for developing effective search tools which structure relevant
data quickly from an ever growing range of unstructured and semi-structured
documents and records. This has lead to information retrieval becoming
a key area of research with the development of new data models like
web query languages and the advent of XML and similar technologies
which aim to guide the future development of the Web in a more constructive
and structured fashion.
| 2. Searching the Web - Search
Engines |
For a vast quantity of people Search Engines have become a part of
daily life but not many people really know about the progression of
these tools over the past ten years or so and not many people know
about the underlying algorithms and constructs which make them work.
The majority of search engines are implemented as Crawler-Based systems
but the term search engine often includes Human-Powered systems such
as Open Directory. The main types of 'Search Engines' are:
" Crawler-Based Systems - Automatic, uses Spidering and ranking algorithms
" Human Powered Directories - Human decision on ranking and relevance.
" Hybrid Search Engines - Mix of the above two.
For the purpose of this publication I will only be dealing with the
history and architecture behind Crawler-Based Systems such Google
as they implement automatic crawls and ranking algorithms.
| 2.1 How they work - Crawler-Based
Search Engines |
Crawler-based Search Engines can be
broken down into three main elements.
" Spider - crawls through Web gathering information
" Search Engine Index - stores gathered information.
" Search Engine Software - runs queries on the indexed data.
A "spider" is a computer program which "crawls" through the Web gathering
information and returning it to a central database which is then indexed.
These spiders which are also called "webcrawlers" or "robots" or "walkers"
or "Wanderers" are vital to the operation of most search engines.
The spider will often return to the site every one or two months and
to check for any changes that may have been made.
All data that the spider finds goes into the second part of the search
engine, the index. The index contains a copy of every web page that
the spider finds and if the spider finds page changes when it returns
to an indexed site, the index is updated with the new information.
The final part of the engine is the Search engine software which is
used to search through the millions of pages recorded in the index
to find matches to a query. The software includes a ranking algorithm
which it uses to rank the pages in order of relevance. Each different
engine uses a different ranking algorithm which is why different engines
give different results to the same queries. The underlying methods
that search engines run on and rank pages by are often a closely guarded
secret and each search engine has its own search interface and uses
different criteria for matching searches with documents. Each may
also differ in terms of search speed and how it ranks results in order
of relevance.
Standardisation of search engines would make searching the vast amount
of Web resources quicker and easier but when searching for uncommon
data it is often recommended that more than one search engine be used.
Meta-Search Engines allow you to search the results given by numerous
different engines to any query at one time.
| 2.1.1 Search Engine Architecture |
The main difference between the Web and standard IR systems is that
all Web queries must be answered without accessing the text i.e. the
use of indices. If this was not the case then copies would need to
be stored locally which would result in high costs or remote pages
would need to be accessed through the network at query time which
is not practical as it would be far too slow. The architecture of
Search Engine's can be dealt with under the following headings:
" Centralised Architecture
" Distributed Architecture
Centralised Architecture
This is the most common type of architecture employed by search engines.
They use a centralised crawler-indexer which searches the Web and
sends new or updated pages to a main server where indexing takes place.
A common misconception relating to crawlers is the fact that they
do not actually move out and run on remote machines rather it runs
on a local system and sends request to remote Web servers. The index
is then built up and it is from the index that any queries submitted
are answered from.
Problems associated
with this architecture:
" Gathering Data
- Dynamic nature of the Web.
" Saturated Communication Links
" High Load at Web servers.
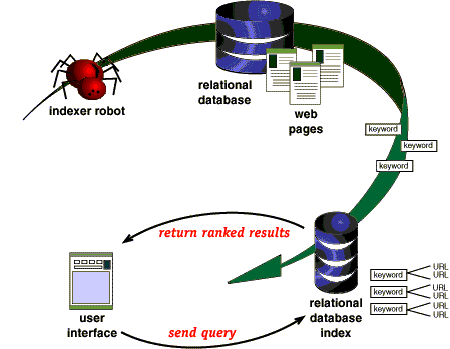
Fig 1. Crawler-Indexer
Architecture
Example of Search
Engine's which use a Centralised Architecture
" Google - most
widely used engine at present.
" Inktomi - powers Microsoft, HotBot and GoTo.
Distributed Architecture
There are several
variations on the above crawler-indexer architecture. The most important
of these is Harvest which uses a distributed architecture to gather
and distribute data. This architecture is more efficient than the
previous crawler architecture because it addresses several problems
such as:
" Web server loads
" Web Traffic
" Coordination
The way Harvest
solves these problems is by introducing gatherers and brokers. A gatherer
retrieves and extracts information related to indexing from one or
more Web servers. This is done periodically i.e. the name Harvest.
A broker on the other hand provides a mechanism for indexing and the
query interface to all the data gathered. Brokers get their information
from gatherers or other brokers and they update their indices incrementally.
A gatherer can run
on a Web server, generating no external traffic for that server and
can send information to several brokers, avoiding work repetition.
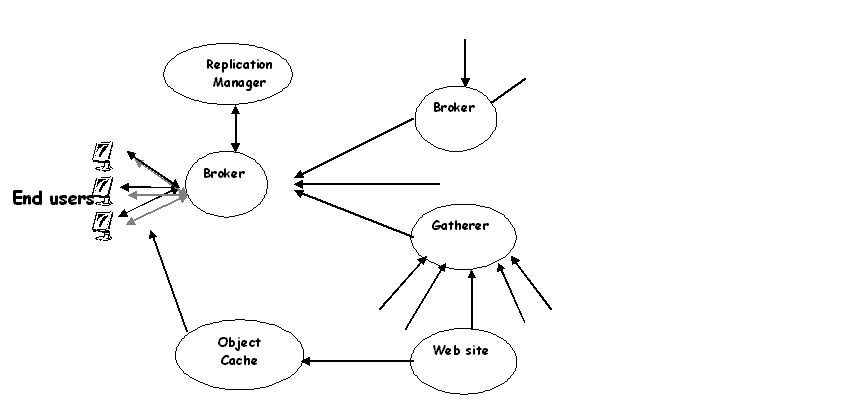
Fig 2. Distributed Architecture: Harvest
Summary: The largest search engines on the
Web at the moment are:
1. Google (46.5%)
2. Yahoo (20.6%)
3. MSN Search (7.8%)
4. AltaVista (6.4%)
5. Terra Lycos (4.6%)
6. Ixquick (2.4%)
7. AOL Search (1.6%) Taken from: www.OneStat.com
| 2.1.2 Ranking including Linkage
Analysis |
Ranking Algorithms
Most Search Engines
use either the Boolean or Vector model or variations of these models
to perform ranking. Ranking is similar to searching in the way that
ranking cannot access text only the index. Ranking algorithms are
often closely guarded secrets and because of this there is not much
public information about the specific algorithms used by current search
engines. It is for this reason that it is difficult to fairly compare
different search engines given the differences between them and regular
improvements in the area.
Each search engine employs different algorithms for determining page
position and these algorithms are subject to change over time.However, there are two general
features which they have in common:
" Word frequency - in a page is important, particularly in
the page title and near the top of the page.
" Number of Links - the number of links to a page is important,
particularly from sites that are in some way recognised as being authoritative
and relevant.
Determining the relevance of a site is an important feature of Search
Engine design and each search engine handles this differently.
Criteria that might
be used in ranking are:
" The Text used in links that point to a page.
" How close the words lie in the text, for searches on phrases of
two or more words.
" The layout of the font used for writing the text.
" The use of H1-H6 tags.
" Whether a page is the root page of a domain.
In 1997 Yuwono and Lee proposed three ranking algorithms (additional
to tf-idf scheme):
o Boolean spread
(Classical Boolean plus "simplified link analysis")
o Vector spread (Vector space model plus "simplified link analysis")
o Most-cited (based only on the terms included in pages having
a link to the pages in the answer)
The first two are
extensions of the original algorithms which include pages pointed
to by a page in the answer or pages that point to a page in the answer.
The Most-Cited algorithm is based on the terms included in the pages
which have a link to the pages in the answer.
Linkage Analysis
The next generation
of ranking algorithms include the use of hyperlink information to
evaluate rank. This is an important difference between the Web and
normal information retrieval databases. Linkage Analysis works by
determining the popularity and quality of a page by measuring the
number of links that point to that page. A relationship is also often
defined between pages if they share common links and reference the
same pages.
Three examples of
ranking techniques based in link analysis:
1. WebQuery
2. Kleinberg
3. PageRank
(1) WebQuery
allows visual browsing of Web pages. WebQuery takes a set of pages
- typically the result of a query and ranks them based on how connected
each page is. On top of that it extends the set by finding pages that
are highly connected to the original set.
(2) The Kleinberg
ranking scheme depends on the query and considers the set of pages
S that point to or are pointed by pages in the result of the query.
Authorities are pages which have many links pointing to them in S
i.e. they should have relevant content. Hubs are pages that have many
outgoing links. This result's in better authority pages coming from
incoming edges of good hubs and better hub pages come from outgoing
edges to good authorities. Take H(p) and A(p) as the authority and
hub value of a page p. The following equations are satisfied for all
pages p:

H(p) - Hub
value of page p
A(p) - Authority value of page p
where H(p) and A(p)
for all the pages are normalised. These values can be determined through
an iterative algorithm, and they converge to the principal eigenvector
of the link matrix of S. In relation to the Web, a maximal number
of pages pointing to the answer can be defined in order to avoid an
explosion of the size of S. (Yates, Neto, 1999)
(3) PageRank
is part of the ranking algorithm which is used by Google. PageRank
works by simulating a user randomly browsing the Web and is based
on certain probabilities. PageRank models the user randomly following
links. The first probability is that the user jumps to a random page
with a probability q or follows a random hyperlink on the current
page with probability 1-q. It is also assumed that the user never
goes back to a previously visited page following an already traversed
link backwards. This entire process can be modelled using a Markov
Chain, from where the stationary probability of being in each page
can be calculated. This value is then used as part of the ranking
algorithm of Google. Let C(a) be the number of outgoing links of page
a and suppose that a page a is pointed to by pages p1 -pn. Then, the
PageRank, PR(a) of a is defined as
q -typical value
=0.15
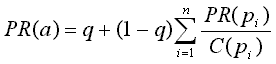
where q must be
set by the system.
(Yates, Neto, 1999)
| 2.2 History of Search Engines |
One of the most
exciting features of the Internet explosion is the timescale that
it all happened in and is still happening in. I can, as with most
people my age remember a time without the Internet and without search
engines and I believe that the Internet will probably be the "television"
of our time meaning that our children will look at us in amusement
when we tell them that we were alive before the Internet boom just
as we look at our parents in amusement when they tell use about the
times before television.
| Date |
Details |
Location |
| 1990 |
Alan Emtage
creates “Archie”, the first search tool which archives
a repository of Internet files by using anonymous FTP.
|
University of Magill |
| 1991 |
Mark McCahill
introduces “Gopher” as an alternative to Archie.
|
University of Minnesota |
| 1992 |
Introduction
of “Veronica” – a search tool that scans gopher
servers for text files.
|
University of Nevada |
| 1993 |
Introduction
of “Jughead” an enhanced version of gopher which
has keyword search and Boolean operator capabilities developed
by Rhett Jones.
Matthew
Gray creates the earliest widely acclaimed Web robot “World
Wide Web Wanderer”
|
University
of Utah
M.I.T
|
| 1994 |
Yahoo
is created by David Filo and Jerry Yang as a way to keep track
of their favourites on the Internet
Brian
Pinkerton introduces WebCrawler. See below
Michael
Maldin creates Lycos
|
Stanford
University
of W.A
Carnegie Melon
|
| 1995 |
Infoseek
becomes the default search engine for Netscape
Erik
Selberg and Oren Etizioni introduce Meta-Crawler.
Excite
is launched and Alta Vista is introduced to public acclaim.
The first
Meta Search Engine – SearchSavvy is introduced
|
University
of Washington
|
| 1996 |
Developers
discover the use of Meta tags to improve search engine ratings.
Inktomi
is founded by Eric Brewer and Paul Gauthier.
HotBot
is launched.
LookSmart,
a categorized directory of WebSite listings is introduced.
|
|
| 1997 |
Ask
Jeeves is introduced with key aims: ease of use, relevance,
precision and ability to learn.
Bill
Gross’ idealab introduces GoTo – first pay per click
search engine
Introduction
of Search Engine ranking software which allows Web site owners
to manipulate their position and ranking within the major search
engines.
|
|
| 1998 |
Open
Directory is launched with the aim of becoming the most comprehensive,
robust directory on the Web.
Larry
Page and Sergey Brin introduce Google a search engine that takes
an innovative new approach to evaluate relevancy.
Direct
Hit is introduced as a new technology which aims to change the
world of searching by analysing the activity of past internet
searches.
Ranking
algorithms start dealing with “off the page” considerations
which leads to Web sites trying to increase their “link
popularity” by increasing their links from external sites.
|
|
| 1999 |
The
Go network is introduced by Disney and utilises InfoSeek search
technology.
The
first public Internet company, NBCi is launched by NBC and includes
the Web service Snap which provides Internet search and directory
facilities.
The first
engine to index 200 million Web pages is launched, it is Norwegian-based
Fast Search.
|
|
| 2000 |
Online
marketers begin to recognise pay-per-click search engines as
an easy, yet expensive approach to gaining top search rankings
on important keywords and phrases.
|
|
| 2001 |
Ask
Jeeves acquires the Teoma search property.
GoTo changes
its name to Overture as the company re-brands itself as an e-business
services company.
|
|
At present Web site
owners and optimisers recognize that the best way to obtain top search
engine rankings is by building and optimising Web sites that have
useful and relevant content. Page designers should include informative
titles, headings, and meta-fields as well as good links. This will
aid the process of ranking algorithms and will lead to more structured,
easily searchable Web indices. This is widely accepted as the best
way forward in web site design.
| 3. Crawling the Web - WebCrawler's |
Web crawling plays
a major part in searching the Web. This is evident from the important
role which they play in the operation of Search Engines. Brian Pinkerton
created the first WebCrawler in 1994 and the development of "WebCrawler"
over the past eight years is detailed in section 3.2 WebCrawler Timeline.
(A)URL Sets
The Crawler starts
off with a set of URLs and from there it extracts other URLs which
are followed recursively in a breadth-first or depth-first fashion.
To make up the URL set Search engines allow users to submit top Web
sites that will be added to the set. The set could also be made up
of popular, common URL's because they will contain information that
will be frequently requested by users. Both cases work well for one
crawler, but it is difficult to coordinate several crawlers to avoid
visiting the same page more than once.
(B)Country Coding
and Internet name
Another technique
is to partition the Web using country codes or Internet names. Once
the partitions have been made one or more robots are assigned to each
partition which is then explored exhaustively.
(C)Crawling
The current fastest crawlers are able to traverse up to 10 million
Web pages per day. The order in which the URLs are traversed is important:
" Breadth-First - Look at all the pages linked by the current
page, and so on. This matches well Web sites that are structured by
related topics. On the other hand, the coverage will be wide but shallow.
" Depth-First - Follow the first link of a page and we do the
same on that page until we cannot go deeper, returning recursively.
(D)Updating
The Web Pages referenced in an index will be from one day to two months
old. They will also have been explored at different dates and may
in fact not exist any more. For this reason, most search engines show
the date when the page was indexed. It is said that search engines
store somewhere in the region of 2% to 9% of invalid links. There
are some engines that learn the change frequency of a page and visit
it accordingly.
| Date |
Details |
| January
27, 1994 |
Brian Pinkerton,
a Washington University student starts WebCrawler in his spare
time. It was originally developed as a desktop application and
not as the Web service it is today.
|
| April
20, 1994 |
WebCrawler
goes live on the Web. It originally had a database with pages
from over six thousand sites.
|
| November
14 1994 |
WebCrawler
reached its one millionth query, this was eight years ago while
today an engine could reach that figure in just minutes.
|
| December
1, 1994 |
DealerNet
and Starwave both decide to sponsor WebCrawler. WebCrawler was
fully supported by advertising on and this kept it in operation.
|
| June
1, 1995 |
WebCrawler
is acquired by AOL. At that time, AOL had fewer than 1 million
users, and no capability to access the Web. It was believed
that AOL's resources could help make the most of WebCrawler's
future.
|
| September
4, 1995 |
WebCrawler
changed its design and first introduced “Spidey”
the WebCrawler mascot.
|
| April,
1996 |
The functionality
of WebCrawler is extended to include the best human-edited guide
for the web: GNN
|
| April
1, 1997 |
WebCrawler
is acquired by Excite from AOL. WebCrawler was initially supported
by its own dedicated team within Excite, but that was eventually
abandoned in favour of running both WebCrawler and Excite on
the same back end.
|
| 2001 |
WebCrawler
is acquired by Infospace after Excite file for bankruptcy. Today
Infospace runs WebCrawler as a meta-search engine and includes
paid links in the search results and they have changed the name
of the mascot from “Spidey” to “Hunter”.
|
Source: http://www.thinkpink.com/bp/WebCrawler/History.html
A Meta-search engine
or multi-threaded engine works by sending a given query simultaneously
to several different search engines, directories and other databases.
After it collects the results it will remove any duplicate links and
according to its ranking algorithm, present them to the user in a
single merged list.
The reason for the development of meta-searchers is because every
search engine indexes different Web pages, so if you use only one
engine you could lose relevant results that another engine might return.
Meta-search engines
differ from ordinary search engines because they:
" Do not have their
own databases and
" Do not accept URL submissions.
Advantages of Meta-searchers
" Results can be
sorted by different attributes such as host, date etc.
" Good for obscure or uncommon queries.
" More informative than a single search.
" Could return more relevant pages than a single engine.
" Save time by running query on multiple engines at once.
Disadvantages of Meta-searchers
" Not all engines
may return results because of the use of quotes etc.
" Not all meta-searchers utilise a ranking algorithm to sort data.
" The Query language which is common to all engines could be small.
Some of the Better
Meta-Search Engines are:
DogPile [www.dogpile.com]
ez2www [ http://ez2www.com/ ]
Vivísimo [ http://vivisimo.com/ ]
Search Queries do
not always have to be based on the content of a page but can also
be based on the link structure which connects Web pages. To be able
to pose these queries a different model needs to be used than those
for content based queries. The most important are:
(1) A labelled graph model which can be broken up into three
areas:
" Nodes - used to represent Web pages
" Edges - used to represent hyperlinks
" Semi-structured data model to represent the
content of Web pages.
(2) A semi-structured data model
" Schema is not given in advance, but is implicit in the data.
" Relatively large schema which changes regularly.
" Schema describes the current structure, but allows for violations
of the schema.
" Data is not strongly typed which means that attributes with the
same name may change type as they are used in different places.
XML falls under the category of semi-structured data model.
Some models for querying hypertext systems have been around since
before the development of the Web but the first generation of Web
query Languages were developed for the purpose of combining content
with structure. The first generation of Web Query Languages combine
patterns that appear within the result documents with graph queries
describing link structure.These languages include:
" WebSQL
" W3QL
" WebLog
" WQL
Source: Modern Information retrieval 1999 [Ricardo Baeza-Yates,
Berthier Riberio-Neto]
WebSQL:
WebSQL models the web site as a relational database. The database
has two relations called the Document and the anchor. The document
contains tuples for each document on the Web while the Anchor relation
has one tuple for each anchor in each document. All tuples are virtual
and cannot be enumerated. Symbols used by the language:
" -> for a link to the same site,
" #> for a link in the same document
" => for a link to another site.
W3QL:
Similar to WebSQL but, uses external programs for specifying content
conditions on files instead of including these in the language. Next
generation will replace these external methods with extensible methods
based on the MIME standard.
WebLog -
Uses a deductive rules language, DataLog, instead of SQL-like syntax
WQL
query language of the WebDB project is similar to WebSQL, but supports
more comprehensive SQL functionality such as aggregation and grouping.
Also has limited intra-document structure querying.
The Second Generation of Web Query Languages which were called data
manipulation languages and concentrated on a semi-structured model.
They do however extend the first generation languages by providing
access to the structure of Web pages.The
main second generation languages are:
" STRUQL
" FLORID
" WEBOQL
" ARANEUS
Source:Web Query Languages, Intelligent Information Integration
[Alan K. Dippel]
STRUQL
" Based on labelled directed graphs. Supports URL's, Postscript, text,
image, and HTML files - Part of the Strudel web site management system.
FLORID
" Prototype implementation of the deductive and object-oriented formalism
F-Logic.
" A web document is modelled by 2 classes, URL and webdoc, as strings.
WEBOQL
" uses hyper tree data structure
" ordered arc-labelled trees with two types of arcs, internal and
external.
" Internal arcs represent structured objects and external arcs are
used to represent references(typically hyperlinks)
" Sets of hyper trees are collected into webs.
ARANEUS
A database project that uses the Ulixes language to build relational
views of the data and then generates hyper textual views for the user
using the Penelope language.
Summary:
The web languages above are too complex to be used directly by interactive
users. This is an area which is being worked on in order to make it
suitable for casuals users. Overall this is an area of data-integration
that has the most potential of making information on the Web available
to the public.
Source:Web Query
Languages, Intelligent Information Integration [Alan K. Dippel]
Up to now the development
of the web has been sporadic and unplanned and Search engines have
provided an effective mechanism for searching this unstructured mass
of information, but with the Web growing exponentially, the focus
needs to change from the way in which the Web is searched to the way
in which the Web is developed. Leading Web site developers recognise
the need for the development of informative, well structured sites
with robust, relevant content but nobody can predict the form which
the Web will take on over the next few years.
At the moment Google is recognised as the worlds most comprehensive
search engine because of its large index and the amount of queries
which it handles on a daily basis. Google also implements a good ranking
algorithm while its site is simple and effective. Nobody knows what
the future holds in store for the Web and for engines like Google
but with the amount of data ever increasing, new algorithms and data
structures will need to be developed to ensure that the ability to
retrieve information grows at the same rate as new information is
being added to this vast resource.
Because of the nature of the Web, planning its development is near
impossible as it would require global support and cooperation from
each corner of the earth, something which has yet to be achieved over
any situation. This means that searching the Web is only going to
get more tedious and difficult unless some form of effective standardisation
is eventually introduced to structure and contain the vast amount
of global information.
New search techniques such as those which examine hyperlinks are hailed
as the way forward when it comes to searching the Web. Again the very
nature of the Web casts doubt in my mind over the long term future
of any of the current methods of information retrieval available because
of the sheer size of the explosion that has occurred. By this I mean
that, development of the Web is still new to the world because ten
years ago nobody could have accurately predicted the situation which
is here today. On the same hand nobody can safely bet money which
guarantees the state or structure which the Web will take in ten years
time.
Personally I believe that their will be a revolution within the World
Wide Web, not a general revolution like before when it became widespread
throughout the world but an internal revolution which will redefine
everything that we currently think about the storage and availability
of information on a global level.
Currently large governments such as that of China see the power behind
the Web and the power which search engines in their current form have.
The fact that, for the first time in history people from all walks
of life have the opportunity to freely access information shows that
the world has been changed for ever. Again, the only problem with
this is the lack of some form of effective standardisation which will
ensure the integrity of content being added to the World Wide Web.
My feelings on the future of searching the web can be summarised as
follows. I do not believe in the long term future of any of the current
search engines or techniques. The names and company logos may remain
but the fundamentals behind the way in which they work will have been
changed so much they will be unrecognisable in comparison. I do not
see this as a bleak future for searching the web but as an exciting
prospect because the future development of the Web is going force
the design of new and innovative technologies which can deal with
such a rapid growth. I believe that these new technologies will have
to be extreme and radical and will require both imagination and expertise
in order to be implemented.
My final thought is that the importance of the Web cannot be underestimated
and the future structure cannot be predicted which has created a time
of uncertainty after the initial boom where the importance of developing
new and energetic search methods is a necessity in order to ensure
the vast wealth of global knowledge remains accessible to every single
person.
Modern Information retrieval 1999
[Ricardo Baeza-Yates, Berthier Riberio-Neto]
MMIR – Dublin City University 2002
http://www.computing.dcu.ie/~cgurrin/
Search engine publications and news
http://www.searchenginewatch.com/
A Brief History of WebCrawler
http://www.thinkpink.com/bp/WebCrawler/History.html
Information Relating
to Gopher -
http://www.knowalot.com/nova/gopher.html
Information on
Google’s features
http://www.google.com/help/features.html
Some Web Searching
Tools:
Google
- The best search engine on the web.
Yahoo!
- provider of comprehensive online products and services to consumers
and businesses worldwide.
Excite
- provides search, news, email, personals, portfolio tracking, and
other services.
Lycos
- develops and provides online guides to locate and filter information
on the Internet. Products enable users to accurately identify and
select information of interest to them.
Netscape
Search - combines results from the Netcenter, Open Directory,
and the Web.
AltaVista
- portal featuring web and newsgroup search engine as well as paid
submission services.
HotBot
- offers users a point-and-click interface, pulldown menus, and the
ability to use plain English terminology for constructing searches.
AOL
Search - search engine and directory.
WebCrawler
| David Reade Computer Applications
Software Engineering - Last updated December 2002 |
|